1. 인공지능 / 머신러닝 / 딥러닝
인공지능, 머신러닝, 그리고
딥러닝은 일반인들이 생각했을 때, 혼란스러운 개념일 수 있습니다. 뉴스와
언론 등에서 인공지능을 이야기할 때도 있고, 딥러닝을 이야기할 때도 있기 때문이죠. 예를 들어, 알파고가 인공지능인가 딥러닝인가에 대해서 설명할 때도
비전공자들에게는 헷갈릴 수 있습니다 (심지어 전공자들에게까지도).
대학 및 대학원에서 배우는 인공지능 과목, 머신러닝 과목, 그리고 딥러닝 과목의 커리큘럼을 보면, 어쩌면 이해하기 수월할 지
모르겠습니다. 일반적으로 인공지능은 4학년 혹은 대학원 1학년 때의 과목으로 개설되면서 Introduction to
Artificial Intelligence로 되어 있고, 머신러닝과 딥러닝은 인공지능을
선행 이수 과목 (Prerequisite)으로 정하는 경우가 많습니다.
즉, 인공지능을 배운 다음, 머신러닝을 배우고, 그 다음에 딥러닝을 배우는 것이 뭔가 더 체계적이라고 할까요? 때문에, 많은 사람들이 인공지능, 머신러닝,
딥러닝의 관계를 다음과 같이 표현하곤 합니다.

함수란 입력과 출력 사이에서의 모델링을 직접 하고, 해당 입력을 넣었을
때 출력을 얻는 것과 같습니다. 예를 들어, F(x) = 3x + 5를
만들고, x에 10을 넣으면 결과로 35를 얻는 과정입니다.
머신러닝이란 사람이 직접 모델링하기 어려운 부분들에 대해서 전체적인 틀을 잡아주고, 많은 수의 데이터를 통해 컴퓨터가 모델을 만들어가는 과정으로 기계(머신)가 학습(러닝)하는 것을
의미합니다. 단순히 2개의 점을 가지고 직선의 방정식을 구하는
것을 넘어 사진, 음성 등을 통해 분류를 하려면 많은 수의 데이터가 필요하고, 이를 처리할 수 있는 좋은 성능의 기계 및 컴퓨터도 필요합니다.

즉, 머신러닝이란 우리가 직접 많은 데이터를 보고, 분석해서 모델을 구체화하는 것이 아니라, Y = ax + b과 같이
일종의 틀만 만들고, a와 b에 해당하는 최적의 값을 찾는
것이라고 볼 수 있습니다.
2. 학습과 실제, 그리고 과적합
머신러닝은 많은 데이터를 통해 학습을 하고, 전혀 다른 데이터를 실제로
모델에 적용하면서 분류를 합니다. 학습을 했을 때 정확도가 95%인데, 실제로 정확도는 어느 정도일까요? 얼마면 될까요?
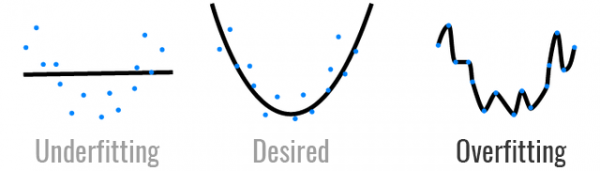
일반적으로 학습을 했을 때보다 실제로 정확도가 높지는 않을 것입니다. 하지만, 학습을 너무 잘해도 문제입니다. 이는 오버피팅 (Overfitting)이라는 용어로 설명이 가능한데, 너무 과하게
분류를 했다고 이해하면 될 것 같습니다. 오버피팅을 설명하기 위해, 언더피팅
(Underfitting)과 바람직한 피팅, 그리고 오버피팅을
그림으로 설명하면 다음과 같습니다.
3. 지도학습, 비지도학습, 그리고 강화학습
머신러닝은 학습하는 방법에 따라서 크게 1) 지도학습 (Supervised learning), 2) 비지도학습 (Unsupervised
learning), 3) 강화학습 (Reinforcement learning)으로 나눌
수 있습니다.
각각의 특징으로는 다음과 같습니다.
1)
지도학습: 정답이 있는 문제를 풀게 됩니다. 예를 들어, 여러 장의 사진을 통해 여자와 남자를 구별해야한다면, 각각의 사진마다 여자인지 남자인지 알고 학습을 합니다. 많은 수의
데이터(사진과 라벨)를 통해 학습을 하다 보면, 새로운 데이터가 들어왔을 때 더 정답에 가까워집니다. 이러한 지도학습으로는
선택을 하는 분류, 예측하는 회귀, 그리고 추천 알고리즘이
해당됩니다.
2)
비지도학습: 정답이 없기 때문에 데이터의 특성들을
파악하거나 유형을 나누는데 도움이 됩니다. 예를 들어, 곤충
사진과 물고기 사진들을 섞어 놓고 구분을 짓는 것은 비지도학습일 수 있습니다. 그리고, 이렇게 특징을 파악한 다음에 라벨을 붙인 다음에 지도학습을 통한 분류를 하기도 합니다. 비지도학습으로는 데이터의 분포를 예측하거나 차원을 축소하는 것을 포함하기도 합니다.
3)
강화학습: 강화학습은 로봇제어에서도 많이 사용되고, 게임에서도 종종 사용하는 학습 방법으로 최적화된 값을 찾기 위해서 보상이라는 당근과 채찍을 사용합니다. 미로를 찾는데, 잘 찾으면 +1을
반대로 가면 -1을 주는 방법이랄까요?
4. 분류 (Classification), 군집화
(Clustering), 회기 (Regression)
머신러닝을 하게 되면 가장 많이 사용하는 것이 분류입니다. 그리고, 군집화는 비지도학습의 주요 특징이기도 하며, 그룹화하는 것을 의미합니다. 끝으로 회기는 데이터를 기반으로 예측하는 것을 말합니다. 분류와
군집화, 그리고 회기는 각각의 예를 통해서 이해할 수 있겠습니다.
1)
분류
A.
수상한 사람과 수상하지 않은 사람 구별하기
B.
자동차와 사람 구별하기
C.
남자와 여자 구별하기
2)
군집화
A.
회사의 매출, 트래픽, 성장성 등을 토대로 회사의 군을 나눠보기
B.
구매 데이터를 통해서 고객의 성향 및 구매 패턴 파악하기
3)
회기
A.
월별 상품 구매 수량과 구매 횟수를 통해서, 다음
주 매입 수량 예측하기
B.
상품 판매량에 영향이 있는 요소들을 통해 가중치가 높은 요소 찾기
5. 확률통계와 딥러닝
딥러닝이라는 용어가 나오기 전에는 인공지능이 없었을까요? 그렇지 않습니다. 사실, 인공지능 과목에서 배우는 상당수는 확률통계에 기초하는 학문입니다. 때문에, 인공지능, 머신러닝, 그리고 딥러닝의 키워드를 선택하라고 하면, 다음과 같이 말할 수
있습니다.
-
인공지능: 확률통계
-
머신러닝: 학습
-
딥러닝: 신경망









최신댓글